Contextual Information Retrieval in the Age of AI
Search finds information. RAG retrieves information for AI. Contextual information retrieval accesses information for you.

Search has largely solved the problem of finding information. AI has exposed a different problem: how to retrieve the information that matters because of what you are currently working on.
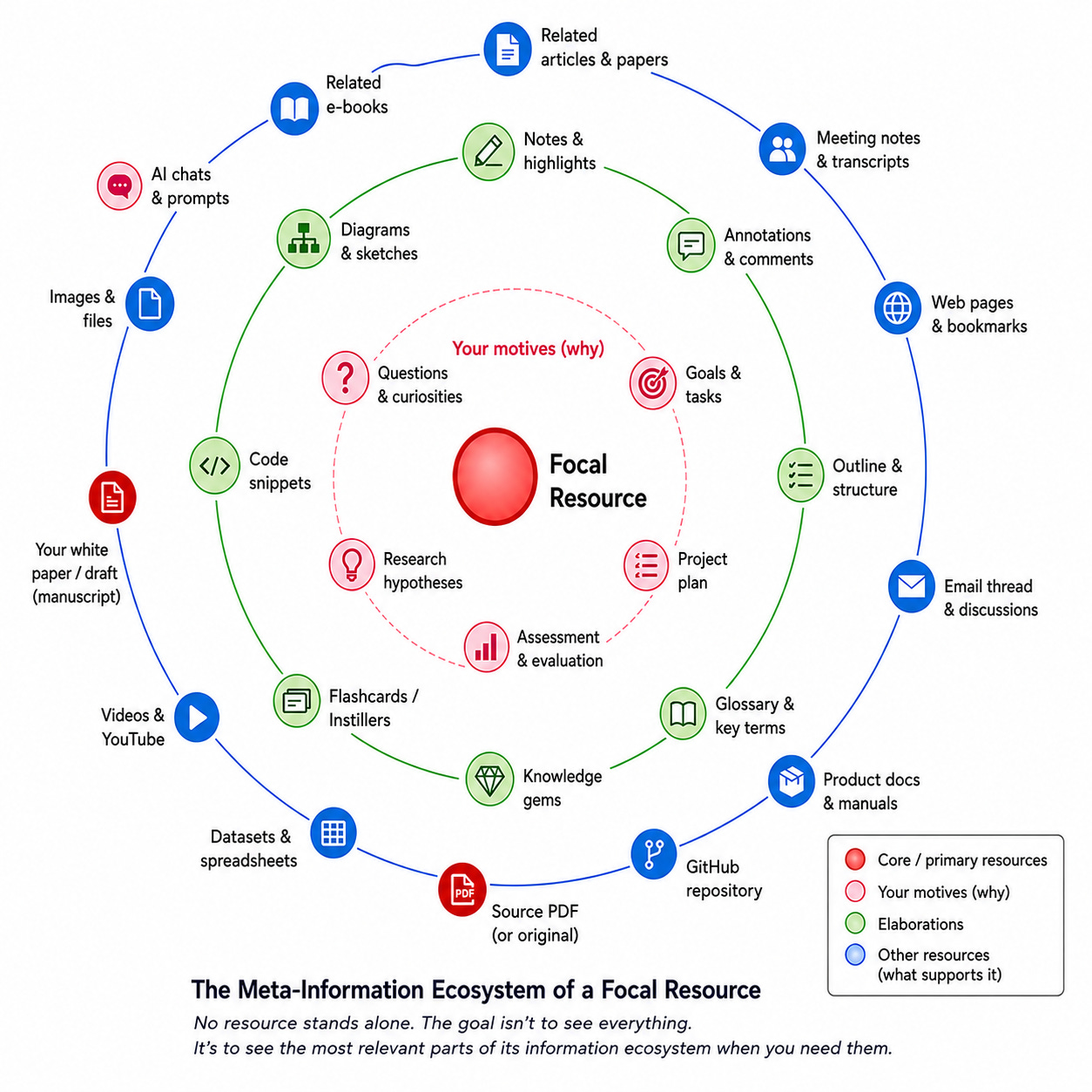
Every research project now accumulates an expanding constellation of PDFs, AI conversations, notes, email threads, meeting notes, transcripts, datasets, web pages, code, diagrams, drafts, tasks, prompts, and AI-generated reports. The challenge is no longer merely finding one of these resources. It is retrieving the information that is relevant because of the current context, which is typically defined by the foreground resource: the paper, draft, email, task, AI chat, or other item that currently has your attention.
I call this contextual information retrieval. More than a decade ago, in my book Cognitive Productivity: Using Knowledge to Become Profoundly Effective, I introduced the closely related concept of the meta-access problem: the problem of efficiently accessing information because of its relationship to the information you are currently viewing. Generative AI has now made that problem much more important.
From information access to contextual information retrieval
Suppose you were reading an important research paper yesterday and now need to get back to it. Traditional information retrieval asks, “How do I find this paper?” That is what Google Scholar, Spotlight, email search, file search, and reference-manager search are good at.
Contextual information retrieval begins after you have found the paper. It asks, “Now that I am looking at this paper again, what else should be immediately available because it belongs with this paper?” That might include notes (in the app of your choice), ChatGPT conversations, Claude Projects, Gemini Deep Research reports, NotebookLM notebooks, Perplexity searches, DEVONthink records, Bookends or Zotero references, OmniOutliner outlines, meeting notes, transcripts, datasets, code, email discussions, grant proposals, entries in your issue tracking system, tasks, calendar events, manuscripts, diagrams, glossaries, and related papers.
These resources are not necessarily connected by keywords alone. They are connected because they participated in the same line of thought, research process, design problem, collaboration, or project. That is why contextual information retrieval is different from ordinary search.
Three complementary kinds of retrieval
Modern knowledge work depends on at least three complementary kinds of retrieval.
Information retrieval answers the question, “Where is this document?” Typical tools include Google, Spotlight, email search, Finder search, and reference-manager search.
Semantic retrieval answers the question, “What documents discuss this topic?” Typical tools include AI search, vector search, semantic search, and embedding-based search.
Contextual information retrieval answers the question, “Given what I am working on right now, what other resources belong with it?” One important mechanism for this is deep relationship retrieval: retrieving resources because of their deep relationships to the current foreground resource.
These three forms of retrieval complement one another. None replaces the others. Search finds documents. Semantic retrieval finds conceptually related materials. Deep relationship retrieval finds the web of resources surrounding the thing you are currently working on.
Where RAG fits
One of the most important ideas in modern AI is retrieval-augmented generation, or RAG. A RAG system retrieves relevant information before generating an answer. That is enormously valuable, but it solves a different problem.
RAG asks, “What information should an AI retrieve before answering this question?” Contextual information retrieval asks, “What information should I be able to retrieve because of what I am currently working on?” Put differently, RAG retrieves information for an AI, whereas contextual information retrieval retrieves information for a human.
These are complementary capabilities. As AI becomes more powerful, both become more important. AI systems need better retrieval to generate better answers. Humans need better contextual retrieval to manage the growing information ecosystems that AI helps create.
Every foreground resource has an information ecosystem
Every foreground resource — a paper, proposal, email, software issue, AI conversation, legal document, presentation, or draft — has an information ecosystem. That ecosystem includes everything that explains it, challenges it, extends it, implements it, summarizes it, cites it, depends on it, or resulted from it.
For example, a manuscript may be connected to AI chats, meeting notes, transcripts, reviewer emails, Bookends references, Zotero collections, DEVONthink records, OmniOutliner outlines, diagrams, glossaries, datasets, code, tasks, calendar meetings, source PDFs, web pages, and related drafts. The challenge is navigating this information ecosystem without repeatedly resorting to search.
That is the meta-access problem in its contemporary form.
Deep relationships, not merely similar text
It is tempting to think that contextual information retrieval is just about finding resources that are textually or semantically similar to the current foreground resource. But that misses the deeper point. What really matters is that these resources are connected by a common episode of knowledge work. A tool may later make those relationships explicit and navigable, but the relationships themselves often already exist in the work.
Two documents that happen to contain the same words have a shallow lexical relationship. Two resources that participated in the same cognitive, scholarly, design, or work process have a deep relationship. A PDF, a ChatGPT conversation, a grant proposal, a dataset, an issue tracker entry, a meeting transcript, and a draft manuscript may share few keywords. Yet they may belong together because they all contributed to the same line of reasoning.
Contextual information retrieval is therefore not primarily about text similarity. It is about preserving and navigating the deep relationships that constitute the structure of your thinking.
Hookmark and deep relationship retrieval
Hookmark was designed for this problem. Rather than asking you to move everything into yet another repository, Hookmark lets you create durable links among the resources that already exist in the applications you already use.
Those relationships can span PDFs, Finder files, folders, notes, AI chats, emails, tasks, calendar events, DEVONthink records, Bookends references, Zotero items, OmniOutliner outlines, web pages, source code, and many other resources. When you invoke Hookmark for the current foreground resource, it shows the resources connected to it. In doing so, Hookmark makes deep relationships explicit and navigable.
This is especially valuable in AI-assisted work. If a ChatGPT conversation helped you understand a paper, hook it to the paper. If a Claude Project helped shape a proposal, hook it to the proposal. If NotebookLM generated useful questions about a source, hook them to the source material. If Perplexity uncovered an important paper, connect it to the manuscript that cites it. The objective is not merely to preserve links. It is to preserve the structure of your thinking.
You are already familiar with links on web pages. Hookmark extends that idea beyond the browser. It can connect resources across many link-friendly applications, meaning applications that expose stable links to their resources. Hookmark works not only with standard links (like https:// links) but with omni-links, deep links that make resources addressable across applications.
Beyond search
Search transformed knowledge work by making individual resources easy to find. Semantic retrieval made it possible to search by meaning. RAG is transforming AI by giving language models access to external knowledge. The next frontier is helping people navigate the growing web of relationships among the resources they create.
Every interaction with ChatGPT, Claude, Gemini, NotebookLM, Copilot, or Perplexity can produce another potentially valuable knowledge artifact. The bottleneck is no longer generating information. It is maintaining contextual access to the information ecosystem surrounding whatever you are currently working on.
That is why contextual information retrieval matters. It is also why the meta-access problem has become more important than when I first described it in Cognitive Productivity. Hookmark was built to solve it.
Executive summary
This article introduced the following concepts.
Contextual information retrieval — retrieving information based on your current working context, typically the current foreground resource.
Meta-access problem — the problem of efficiently accessing information because of its relationship to the information currently in the foreground.
Deep relationships — relationships among information resources that arise from a common cognitive, scholarly, design, or work process, rather than merely from lexical overlap, semantic similarity, or temporal proximity.
Deep relationship retrieval — a principal mechanism for contextual information retrieval, in which resources are retrieved because they have deep relationships to the current foreground resource.
Foreground resource — the document, note, AI conversation, email, task, web page, manuscript, or other resource that currently has your attention.
Information ecosystem — the network of resources surrounding a foreground resource, including AI chats, notes, emails, tasks, datasets, drafts, diagrams, glossaries, code, and related documents.
Information retrieval — finding a known resource, typically through keyword or file search.
Semantic retrieval — finding resources because they are conceptually related to a query.
Retrieval-augmented generation (RAG) — an AI technique in which retrieved information is supplied to a language model before it generates a response.
Knowledge artifacts — the intellectual products of knowledge work, including AI conversations, annotations, drafts, reports, diagrams, code, notes, datasets, and summaries.
Link-friendly applications — applications that expose stable deep links so their resources can participate in a larger information ecosystem.
Omni-links — app-specific or standard deep links that uniquely identify resources across applications, enabling tools such as Hookmark to connect them into a navigable knowledge graph.
Hookmark — a contextual information retrieval system that uses deep relationship retrieval to make the information ecosystem surrounding a foreground resource immediately accessible.